Google is introducing Gemma 4 in four adaptable configurations—Effective 2B (E2B), Effective 4B (E4B), a 26B Mixture‑of‑Experts model, and a 31B dense model—giving developers flexibility across a wide range of use cases. This new generation goes far beyond basic chat, enabling complex reasoning and agent‑driven workflows.
Google has optimized the 26B and 31B Gemma 4 models to deliver state‑of‑the‑art reasoning on accessible hardware. The unquantized bfloat16 weights run efficiently on a single 80GB NVIDIA H100 GPU, while quantized versions are designed to operate natively on consumer‑grade GPUs—powering local IDEs, coding assistants, and agent‑based workflows.
The 26B Mixture‑of‑Experts model is tuned for low latency, activating only 3.8 billion parameters during inference to achieve exceptionally high token throughput. In contrast, the 31B dense model prioritizes maximum output quality, providing a strong foundation for advanced fine‑tuning and high‑fidelity applications.
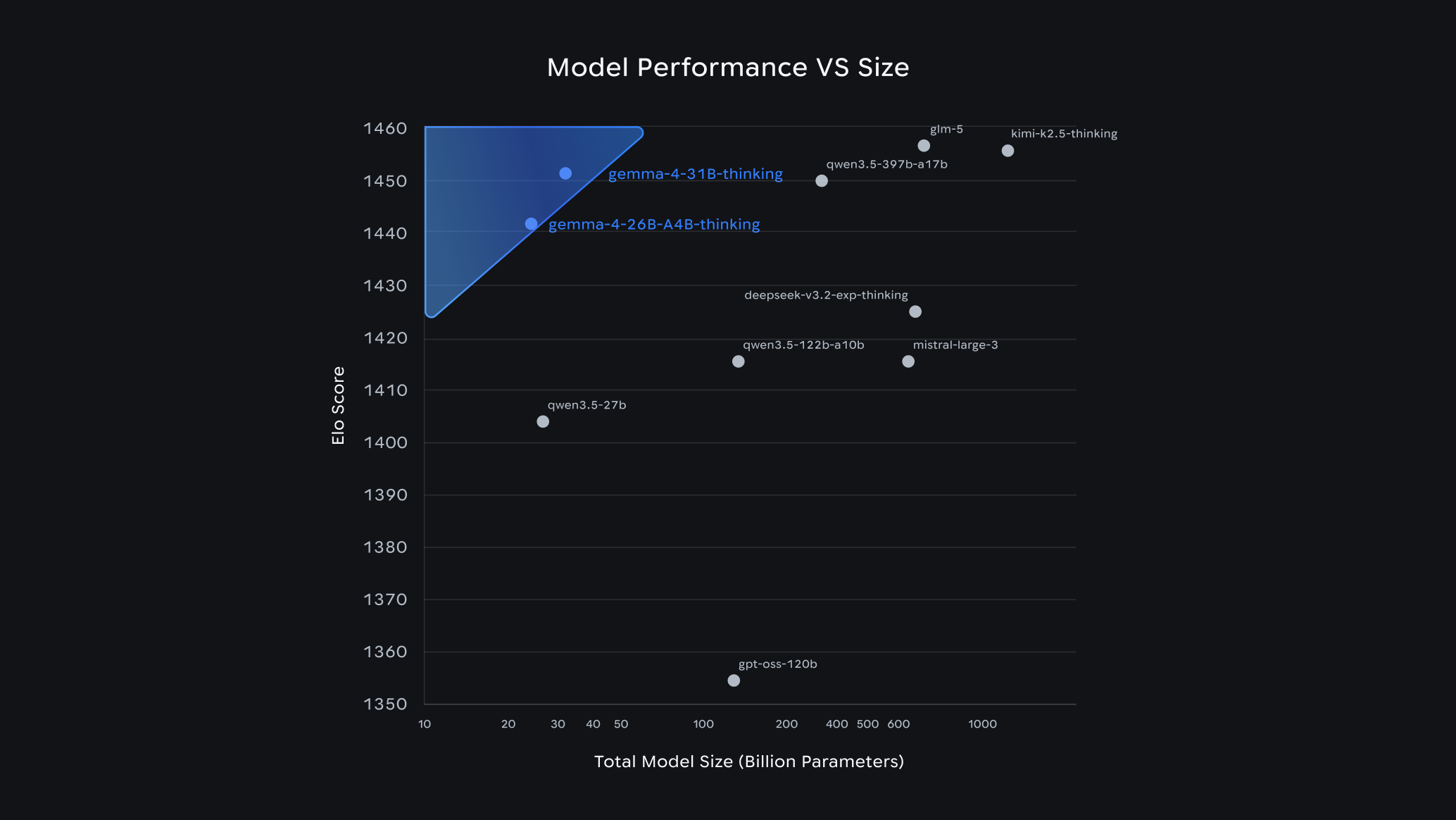
The larger models set a new standard for performance at their size: the 31B model currently ranks third among open models on the Arena AI text leaderboard, with the 26B model close behind in sixth place—outperforming models many times larger. For developers, this translates into exceptional intelligence per parameter, delivering near‑frontier capabilities while significantly reducing hardware requirements.
Gemma 4 represents Google’s most capable open model family to date. Built on the same research foundations as Gemini, these models deliver exceptional intelligence‑per‑parameter, meaning developers can achieve advanced reasoning and agent‑style workflows on far less hardware than previously required. This efficiency is already reflected in community benchmarks, where Gemma 4 models rank among the top open‑source performers despite being significantly smaller than many competitors.
One of Gemma 4’s most significant aspects is its Apache 2.0 license, which grants commercial freedom and full control over data, infrastructure, and deployment choices. Organizations can fine‑tune, distribute, and run these models wherever they choose either on‑premises, in the cloud, or at the edge—without restrictive terms.
Despite being open, Gemma 4 follows the same rigorous security and safety standards as Google’s proprietary models, offering enterprises a transparent yet dependable foundation.
Gemma 4 integrates seamlessly with popular tools and platforms, including Hugging Face, Ollama, vLLM, llama.cpp, Android Studio, and Google Cloud services. Developers can experiment instantly, customize models for specific tasks, and scale to production without changing their workflow.
Gemma 4 is released in four sizes, each optimized for different environments:
- 26B MoE and 31B Dense models deliver frontier‑level reasoning on personal workstations or single high‑end GPUs, with quantized options for consumer hardware.
- E2B and E4B models are built for edge and mobile devices, running fully offline with low latency and minimal power usage ideal for phones, IoT hardware, and embedded systems.
This range allows developers to deploy consistent AI capabilities from cloud servers all the way to on‑device experiences.